Build vs Buy: Do you really have to choose when it comes to instrument integration software?

At some point, every biotech and pharma lab faces the same question when it comes to integrating data from their analytical instruments: should I buy software or build something in-house?
Usually, this question comes up when a lab hits a certain critical mass of workflows, instruments, and staff. The amount of data that scientists generate—and the overhead to maintain, store, process, and use that data—becomes overwhelming. As a result, the lab needs to collect and centralize instrument data via infrastructure that’s comprehensive, robust, secure, and yet flexible. Unfortunately, neither option for lab data infrastructure—buying from an external vendor or cobbling together a “homebrew” solution—is perfect.
- The Out-of-the-Box Buying Approach: With the traditional “buy” paradigm, labs get an externally maintained, out-of-the-box solution that’s typically more affordable than hiring full-time engineers to build something from scratch. However, almost all third-party software limits user customization and direct interaction with the underlying code. And it rarely provides full coverage horizontally across instruments and vertically across workflows. Specifically, third-party software may only integrate certain instruments, fail to integrate analytical tools and scientific software like electronic lab notebooks (ELNs), or have restrictions on the kinds of workflows it can handle. All of these shortcomings can leave you scrambling to adjust your standard operating protocols (SOPs) to the vendor’s needs and requirements.
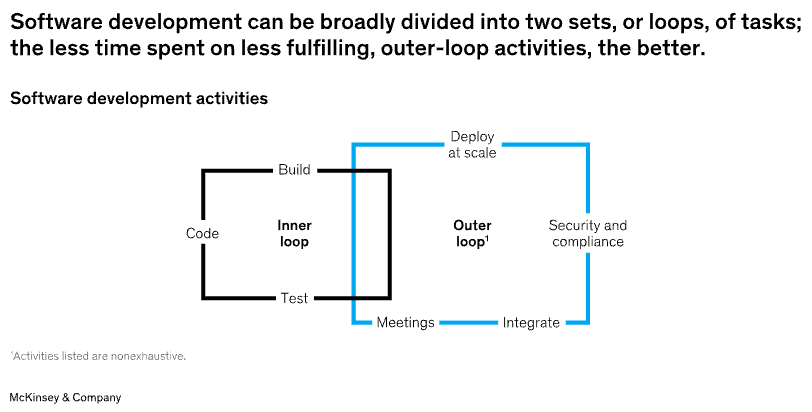
- The Build-it-Yourself Approach: Hearing the downsides of external software, building something from scratch may seem more appealing. A homegrown solution can be fully customized, with more control over the functions. Although the in-house approach may allow for more direct oversight in the short term, it can be painful in the long term. Building a platform yourself comes with costs: literal costs. Hiring engineers to design, build, and maintain software is tremendously expensive. The time your team will spend on maintaining, deploying, and integrating the basic infrastructure and software takes away from the time they could spend more valuable activities: improving the platform, adapting it to changes in scientific workflows, or addressing other, more strategic IT and tech decisions within the company (as illustrated above).
Beyond time and cost, homegrown solutions are rarely fully planned out at the on-set and instead grow in a more ad hoc fashion. This also means they often don’t scale easily with the company as it grows. Case in point: what happens if your key engineer leaves? They may take with them the knowledge needed to operate the platform, leaving you without options to continue using, maintaining, and growing your solution.
Instrument Integration: Should I Build Or Buy?
Most existing options for instrument integration today leave biotech labs in a pickle. Companies want the cost savings and convenience of buying, with the customization and comprehensiveness of building. Before moving forward, consider these five questions:
1. Do you have an existing data strategy?
True data integration takes massive amounts of institutional buy-in, internal culture changes about data, and time. But without a strong foundation of instrument data and a plan for how all that data is housed, structured, and used, even the most complex data models and tools like AI/ML are hobbled.

That’s why companies should think about their data infrastructure and strategic goals before making a significant investment in lab automation or ELNs. We’ve seen biotechs have the most success with instrument integration and data infrastructure when they’re thinking about their data and workflows on a higher, more strategic level. For example, a key consideration is the minimum requirement for data–is it strictly for R&D, or is that data powering a complex production process? Infrastructure should depend on the institutional data goals and demands. Above, we provide a basic framework for mapping out your data strategy and the tech stack subsequently needed to achieve it.
2. Are your instruments network connected, but overdue for streamlined data management and automation?
Most modern instruments—flow cytometers, plate readers, and bioreactors—will have connective capabilities. That said, they may come with output data trapped in locked-down files or be reliant on software from the original equipment manufacturer (OEM), both of which can hinder integration. Regardless, if the majority of your lab’s instruments have some kind of network connectivity, it’s time to think about integrating that instrument data through automation.
Why? If you’re hearing about the same frustrations consistently and your scientists are wasting precious time on administrative tasks like dragging and dropping files, it’s a good sign that your data management needs an upgrade. Automation—which runs best on well-kept data—can reduce workflow headaches, operational errors, and busywork.
3. Does your team code?
One of the biggest hurdles for any data strategy is data fluency. In other words: does your existing team have the expertise to build software from scratch? For many labs, the answer is “no.” If that’s the case, then you may want to look for solutions that are a little more out-of-the-box, code-flexible, and have a UI/UX that’s friendly for non-technical users.
However, companies should always expect some level of coding, even for so-called “no” or “low” code tools. Wet lab data is too messy and complex for no-code tools, and science changes too quickly for software to be rigid and stagnant. If you do go the route of building in-house, you’ll nonetheless need to consider a tech stack, but it will look quite different, including cloud infrastructure that will need to be fully managed. On the other end of the spectrum, there are biotech companies with teams of software engineers. These teams come with their own set of challenges (i.e. code versioning, data provenance, system uptime, etc.), mainly related to orchestrating and tracking new builds, updates, deployments, and debugging.
4. How standardized are your workflows?
Before investing in any software, labs should understand how standardized their individual workflows are (see the guide below) Another way to think about it is to map your workflow against the taxonomy of data integration we provide above, and assess the level of variability for a given step. If they’re not standardized, it’s essential to establish clear and reasonable parameters of success for each before investing resources into instrument data integration–whether labs opt to build or buy.

Looking back at our earlier example, for creative, early-stage R&D workflows, labs may simply need to apply software towards data extraction/storage and for final record of their data (e.g. ELNs). But for more established processes, labs need more–they’ll want to maximize integration and automation of their data across the entire workflow to make it more actionable (the full ETL). One thing we’ll point out here to help manage expectations and inform strategy, is that analysis is typically where workflows really fan out and are notoriously difficult to standardize.
5. Do you really need to choose between building and buying?
At Ganymede, we reject the binary choice of build vs. buy. Instead, we ask: why not both?

Ganymede’s platform unifies the fundamental, and commonly-used, elements of data infrastructure found within most life science labs. This allows labs to minimize the most headache-inducing parts of instrument data integration:
- Getting new instruments online and connected to a data lake
- Contextualizing instrument data
- Migrating to a new LIMS or ELN
- Making changes to instrument connectors
- Deploying software updates
However, our platform also remains flexible. While the most annoying, repetitive, and difficult to set up and maintain parts of instrument data integration are taken care of, labs still retain the capability to customize and build their own pipelines from scratch with our core Lab-as-Code technology. Or not—we can also handle any custom coding project and the managed services to implement it, if needed.
As we like to say: not a coder? Not a problem.
Plus, we can help you ask the right strategic questions before diving into instrument integration, ensuring that your infrastructure is built with your research goals in mind from day one. To further illustrate our point, here is a schematic showing our customizable and complete “back-end-in-a-box” approach to instrument integration:

….and what it would take to build something comparable using AWS equivalents:

Lab Data: Both Instrumental and Integral
Data is the lifeblood of any scientific organization. Without it, labs cannot make meaningful discoveries, generate IP, file for INDs, or even put together presentations. But if that data isn’t FAIR (findable, accessible, interoperable, and reusable), then labs cannot ensure data integrity or empower scientists to spend more time on what matters: actual science.
Instrument integration is one of the first (and most important) steps a lab can take to becoming fully FAIR. Centralizing data, tracking and associating all the complex metadata related to workflows, and making that information accessible and reusable to all is a massive challenge though. While it can be tempting to think of infrastructure for instrument data as a buy vs. build dichotomy, science is too complex for either. By embracing the best of both approaches, and by embracing solutions that prioritize customization, labs can create infrastructure that scales and meets the needs of everyone in the lab, from no- and low-code users, to proficient coders.
If you'd like to see our Lab-as-Code approach to lab data management, make sure to check out our latest interactive demo.