Wondering how to implement the right lab automation stack?
Here’s a 5 step approach for bringing high throughput to your R&D.

Automation is a buzzy word in biotech and biopharma. When properly implemented, automation promises many benefits to labs, including:
- Time savings, allowing scientists to spend more of their day on actual science
- Increased scale, such as conducting more experiments or spinning up new workflows quickly
- Better productivity, enabling existing staff to operate more efficiently and do more
However, many people view automation as a silver bullet for everything that’s not currently working within their lab. At Ganymede, we often run into folks who think that by bringing automation into their lab, things will magically get better.
We wish that were the case, but the truth is that successfully automating a lab takes a lot of work. It’s not a one-step, one-stop-shop process. Lab automation requires several different foundational elements, including strong data management, a vision for data strategy, some level of standardized workflows (e.g. a repeatable, well-defined manufacturing process), and, of course, the right software and hardware tools to implement it.
The Lab Automation Sandwich
Once biotech organizations have some form of data management/strategy and standardized workflows, they need to build their automation tech stack. In less technical terms, we like to think about this stack as an automation sandwich composed of multiple layers. Yes, a sandwich—not the most glamorous of metaphors, but one that we find accurate and illustrative of how lab automation fits together. Bear with us, we’ll do our best to refrain from any (too many) puns about lunch.

There are five layers to every lab automation sandwich:
- Systems of Record
- Design of Experiment Systems
- Physical Automation
- Data Automation
- Systems of Record (yes, again! We’ll explain why below.)
In this post we’ll walk through each of these layers step-by-step, discussing why they matter and how each contributes to an automation-ready tech stack.
Step One: Establish Systems of Record
At the top and bottom of every automated lab, there is a system of record. Think of this as the bottom layer of bread that lays the foundation for the whole sandwich. This crucial layer of software serves as a shared repository of knowledge within a lab. It’s where scientists generate and annotate experiments, and where everyone within the lab has access to experimental data, analyses, and more. Critically, this layer is often the source of key pieces of metadata that serve as the unifying thread throughout each automated workflow.
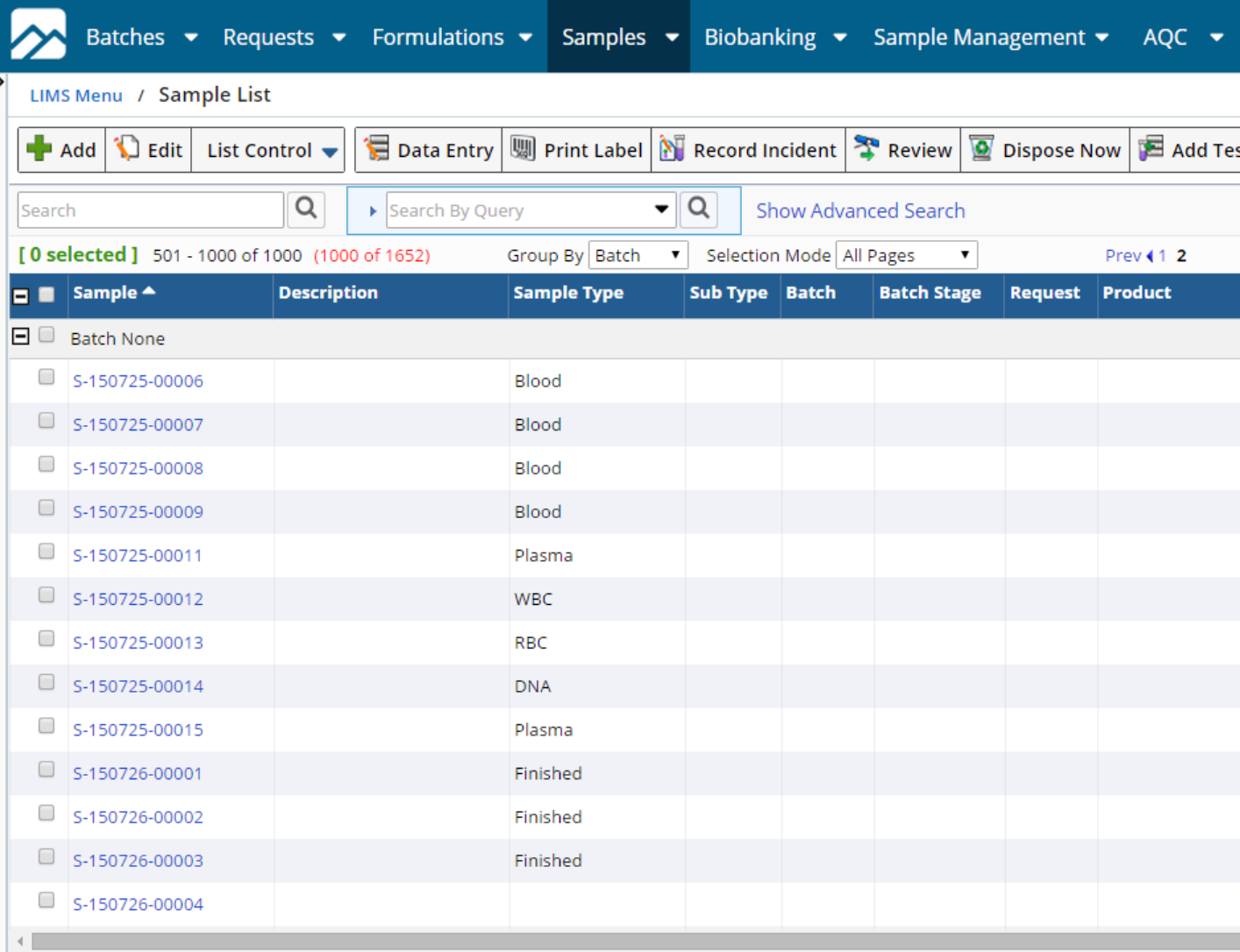
Examples of systems of record include:
- Electronic lab notebooks (ELNs), such as Scinote and Benchling
- Laboratory information management systems (LIMS), such as STARLIMS and ThermoFisher’s SampleManager
- Manufacturing execution systems (MES) such as Apprentice and MasterControl

These days, most labs already have some piece of system of record software in place. While there might still be record-keeping happening by hand on paper, that information will eventually make it into an ELN, LIMS or MES through manual entry (although whether that information is entered correctly or with full context is another question).
Regardless, without a system of record, labs can’t take advantage of automation. So if you’re new to lab automation, start with finding the right system of record for your organization. And if you already have one in place, it’s time to move on to step two.
Step Two: Set Up Design of Experiment Systems
A lab’s data is only as good as the experiment that generated it. Once a lab has implemented a system of record, the next step is to find the right design of experiment software.
With this software layer, labs can lay out experimental plans in a comprehensive manner, accounting for variables, each step in the workflow, and other important criteria. If the ELN or LIMS system is where a lab’s data goes for sharing and analysis, design of experiment software is where labs ensure that data is generated in a high-quality, repeatable, and statistically powerful way (we’re looking at you p-value hackers).
By codifying a given experiment into a set of repeatable processes that lab operators can understand, design of experiment software enables automation engineers and scientists to translate that SOP into a machine-readable method/protocol. A good example of this kind of software is Synthace or JMP.

One thing to note: many ELNs and LIMS also offer design of experiment functionality, so it's worth checking there first.
Step Three: Invest in Physical Automation
Now that your lab has a place to share data AND generate experimental designs, it’s time to actually do some lab work. This is the step where real data gets generated through real workflows and processes. Welcome to the workflow automation layer, where there’s actual, well, automation.

If you’re still thinking of our sandwich analogy, the lab automation layer is the thickest part of the whole meal—it’s all the options you have for the middle part of the whole stack. Rather than a single piece of software, this step is actually composed of lots of different elements of software and hardware and protocols, including:
- Robotic elements, such as liquid handlers that automate sample prep or more complex works cells that combine liquid handlers with analytical instruments and robots
- Laboratory execution systems (LESs), like Cellario, Momentum, and Apprentice’s Tempo LES that enable scientists and automation engineers to define workflows and run experiments on them
- Digital orchestration platforms, like Artificial and Green Button Go that manage work between manual and automated sources
- And more
All these different tools and technologies should start to bring automation to experimental workflows.
Step Four: Automate Your Data
Once a lab is generating data from experiments running at scale, some big questions arise about the storage, management, and quality of that data. All too often, data comes off instruments and becomes siloed through old school processes, such as downloading data to a USB or entering data in Excel. Even in cases where data is automatically uploaded from an instrument to cloud storage or to an ELN or LIMS, it’s essentially a raw data dump. Sometimes the files are locked in a proprietary OEM format, and they often lack detailed metadata that provides the context for the experiment. The result is that most labs have data scattered all over the place.
Let’s think about 3 common considerations for labs when they purchase traditional, physical lab automation systems to illustrate this point further.
- Higher experimental throughput - how can you expect to meaningfully introduce higher throughput with the low throughput data processing?
- Flexible enough to match workflows - are the processes really that flexible if the data pipelines for handling them are static and hard coded?
- Standardize complex workflows - how standardized can the protocols be with manual data management steps in between, let alone the lack of traceability?
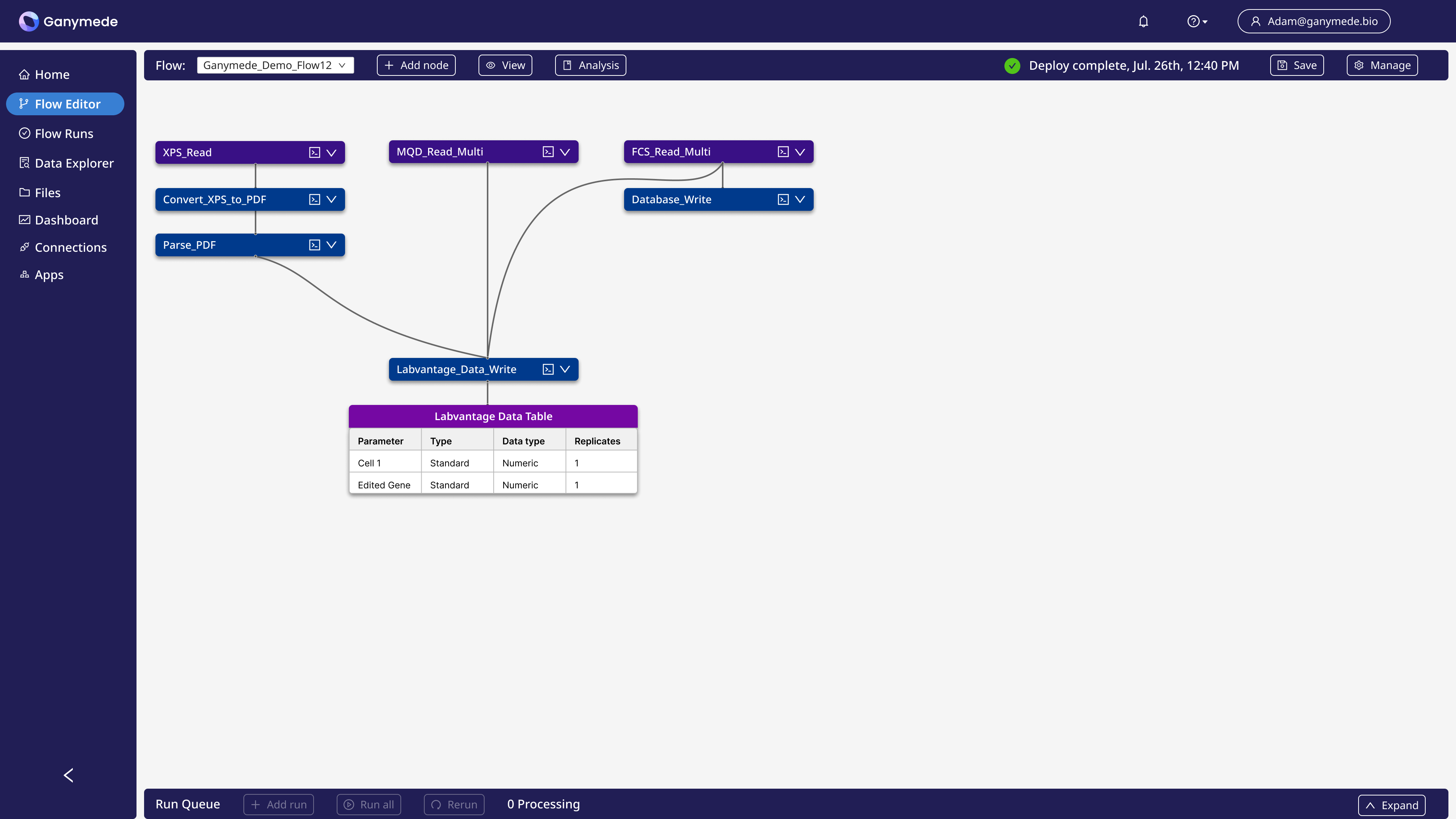
That’s why labs should think about data automation as their fourth layer. In this step, platforms like Ganymede apply automation to the data itself. This can look like automatically:
- Pulling data from instruments, such as flow cytometers
- Cleaning that data and annotating it with crucial metadata
- Storing and structuring data in the cloud
- Streamlining data management in and around analysis
- Automating the entry of key results into your ELN/LIMS/MES
- Customizing and updating your data pipelines to adapt to your physical workflows
- And more
Not all steps need to be automated. For example, scientists should be able to run their favorite analysis tools like FlowJo manually, while the data management gets automated way.
Without data automation, you’re unable to handle the reams of data generated by your robotic hardware and orchestration systems. By automating data, labs can make discoveries faster and operate their labs much more efficiently. Every speck of data is FAIR—findable, accessible, interoperable, and reusable. . At Ganymede, we’ve actually found that automating data saves scientists 20 percent of their time at the bench and helps life science companies move 10 percent faster to IND or to market.
Step Five: Feed Back Into Your Systems of Record
Every sandwich needs a top layer and a bottom layer to hold everything together. That’s why systems of record come back to serve as another slice of bread in this analogy. Once data management is automated, all that FAIR, beautiful data can be fed back into your lab’s ELN, LIMS, or MES. With well-organized, high-quality data at their fingertips, everyone—from the IT department to developers to lab managers to bench scientists—is working from the same version of the truth.
Lab Automation: The Future of Science
Science is more complex and interdisciplinary than ever before. Life science labs today are working across biology, chemistry, and more. The data they generate is some of the most valuable in the world, with the potential to cure diseases and bring new hope to patients. These ground-breaking labs are also facing the same pressures as many other industries: the mandate to do more with less, move faster than their competitors, and deliver value to patients and the market.
Data automation can help companies on all fronts. When data is intelligently generated, organized, and analyzed, labs have a better view of their science. And with a better view of their science, they have a better chance of seeing the next big discovery clearly. Labs should invest in their ideal sandwich-style tech stack, thoughtfully integrating each of the five layers described in this post. And if you’ve read this before lunch, we hope we didn’t make you too hungry, and if you’re reading this after lunch, we think we have a pretty good idea of what you’ll be having for dinner 😀.
Watch our webinar to learn more about the challenges and trends in lab automation from experts across the lab auto tech stack.