
AI Agents vs GPT‑5: What Scientists Actually Need
LLMs seem to have plateaued, in a good way: they’re already near-perfect if you give them the right context, and the billions of dollars required to train better ones offer only marginal improvements at this point. GPT-5 won’t really change things even though it’s rumored to be coming out this August. The impact of newer models has dwindled over time.
But this is where AI agents are so exciting. Cursor and more recent tools like Claude Code have shown the power of agentic coding, and how much more LLMs can do when they’re given the ability to use tools, gather their own context, and execute iteratively. It’s an entirely new product.
And AI agents don’t take billions of dollars to improve. They’re application layer logic: agents are a sequence of steps with tool uses and decisions for the AI to make, and the sequence of steps and tools to use are just business logic any company can write. This S-curve is far less constrained!
Agentic capabilities will be critical for scientific applications: nowhere is context more fragmented and important than experimentation, which is like a human version of context gathering. Scientists hold incredible dimensions of context in their head. AI has a long way to go here as I discuss in this post. But once it can gather context more independently, a whole new world will open up.
In this sense, agents could be more transformative than the underlying LLMs, though they’ll take more time to refine since they’re less general-purpose. I’m very excited - in 2024, I personally saw LLMs as very powerful, but clearly overhyped in terms of long-term impact. With agents in 2025, they’re certainly overhyped now, but the hype might be accurate for the long term (much as the dot-com bubble burst, but the internet as of today has largely fulfilled the dream, just with different companies. See Pets.com vs Chewy.)
What are agents?
First, a word on definitions. Terms are evolving quickly, but AI Agents are usually defined as an LLM running in a loop with the ability to use tools or make decisions.
I like to extend this definition somewhat: an AI Agent is a directed graph (a flowchart) of steps, and at each step, the LLM:
- May have a piece of its prompt customized or information given to it
- Can use certain tools
- Can decide when to end the step and where to go next if there’s branching
In this definition, the conventional version of an “LLM running in a loop” is just a one-step version of the broader directed graph. And tool usage or prompt customization can be extrapolated to broader capabilities like memory management (in the sense humans have memory - not like RAM) that give the agents more and more ability to flexibly manage what context they see.
AI Agents at Ganymede

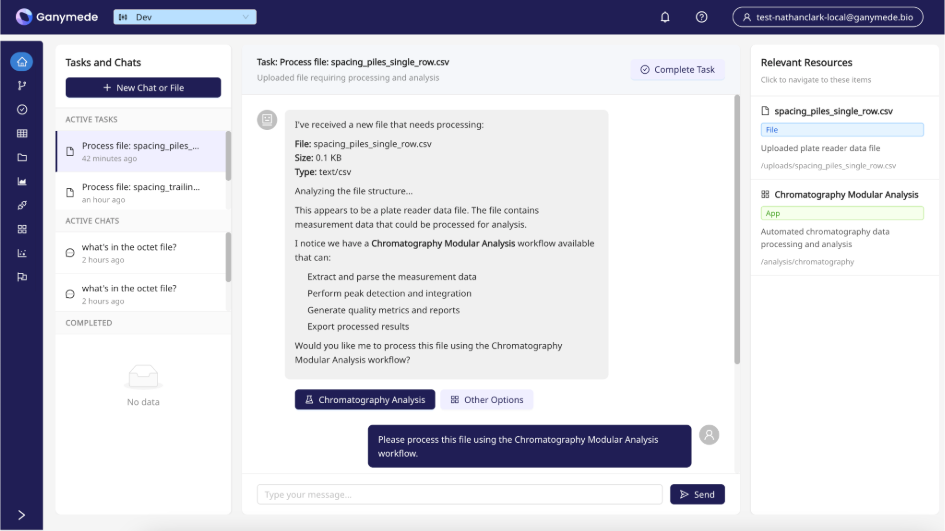
We’re currently developing an AI Agent for generating or modifying charts in our Modular Analysis apps, which run on Holoviz Panel. The structure of this is at right.
Most of the work to be done here is refining how the tool usage works and giving the LLM enough context: telling it when to ask clarifying questions of the users, or letting it know the versions of the packages installed in the environment for charting. Again, once the LLM knows this via its context window, it’s nearly perfect at generating the right code, especially given some iterations to correct bugs. It just needs the context.
And once it works, it really works. Check out our in-development workflow for an agent to modify our Chromatography modular analysis app. Seeing the chart you need pop into the app in real time is incredibly cool.

Context & AI Agents at the Lab Bench
This gets to the heart of the problem and potential in science. When you’re running some experiment, you’re trying to learn something new. Not only is that “something” invisible context, but your motivations for running the experiment and reasoning behind how you’d interpret certain data are wrapped up in past iterations of experimentation, literature search, learned knowledge, and word of mouth.
Scientists are already connecting a very wide net of facts and suspicions when they form hypotheses or determine what they need to do to learn more information. And as much as running experiments is hard, knowing what experiments to run and why is also hard - and probably itself requires lots of experimentation. And when you’re interpreting a result, you need to consider everything from past experiments to temperature in the room.
All of this means that for an AI Agent to contribute productively in a way that’s more than just order-taking, such as dictation or literature search, it also needs to have ways to get as much context from you as possible. It has to read your ELN, it has to have transcripts of your meetings via AI dictation apps like Granola, it has to be able to run its own literature searches for its own purposes to gather context that you learned in grad school, but it needs to learn freshly.
The future of making AI and agents useful in benchtop science therefore runs through these context gathering tools and modalities. And again, once it has enough context to match the model of the world in your head, it can probably do just as well as you or better. But as with any scientist, human or AI, you’re mostly not drawing conclusions for some Eureka moment - you’re deciding what experiment to run next given your resources and timetables, and then doing it. Similarly, this context-gathering push will mostly assist in getting AI agents to the point where their ability to suggest or help execute experiments (e.g. by designing a liquid handler protocol, or reading chromatograms) will actually be useful.
Paths forward for context
Context gathering tools and modalities could include:
- Microphones and cameras everywhere - at the lab bench, in your glasses, in the hallway. It sounds dystopian, but once people realize how useful it is, it’ll probably quickly become a norm
- Clean APIs and MCP servers for all the apps you use, from your ELN to your analysis tools
- Browser and computer use tools for agents to be able to explore physical lab PCs
- Mobile robotics to let the AI access a physical part of the lab
- Additional environmental or instrument sensors from folks like Elemental Machines
- Automated literature & knowledge harvesting compiling an internal summarized library for companies of relevant literature
- AI agents that proactively think about their context base and identify where they need to know more - and actually ask you questions during your day
There’s probably a startup in each of these that could go well beyond science. We’re building some of these and others are too - and maybe you are as well! If you’re interested to riff on any of this, drop us a line.
What’s Next?
If you’re interested to learn more, we’re running a webinar on Wednesday August 6th (register here!). Or, reach out to us at hello@ganymede.bio to learn more.